Hivemind - Cursor for teams
Organization-wide knowledge-sharing AI text editor with mixture-of-experts (MoE) orchestration.
I built this because I was frustrated watching developers in large organizations repeatedly solve the same bugs. It happens the same way - someone spends hours debugging a dependency issue, fixes it, and then three weeks later their teammate hits the exact same problem and starts from scratch. It’s incredibly wasteful.
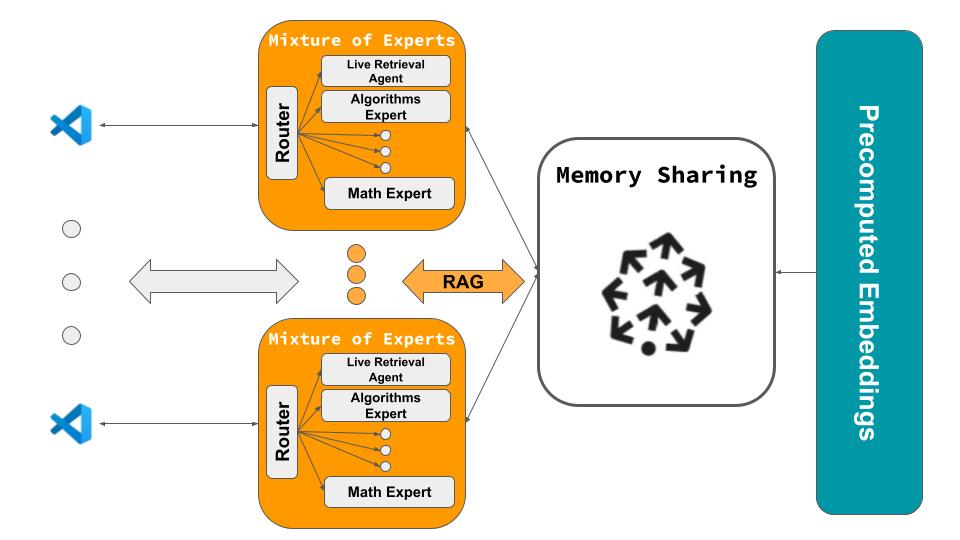
So we built HiveMind, which is essentially Cursor but with shared organizational memory. When someone solves a problem, that solution becomes instantly available to everyone else through a centralized context system.
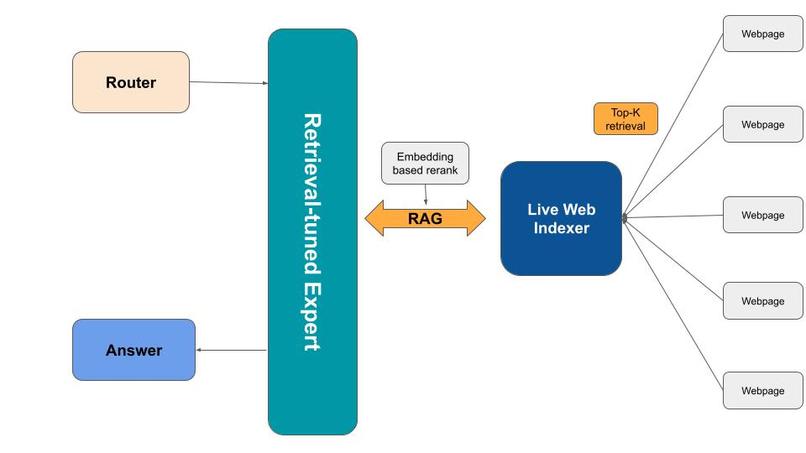
We used OpenAI’s swarm model (literally the day after it was released) to create specialized expert agents - Systems, ML, Frontend experts that understand different problem domains. The real technical challenge was getting everything to work together in real-time. We integrated Continue’s TypeScript frontend with a Python FastAPI backend connected to Pinecone for vector storage, then figured out how to stream responses from the swarm model back to the editor without breaking the user experience.
The streaming piece was the most tricky since we had to handle asynchronous operations between a static expert model call and real-time frontend updates and it taught me a lot about route management and request handling. We deployed on Render for hosting the database for the hackathon.